多元线性回归模型(机器学习线性回归原理介绍和功能实现)
多元线性回归模型(机器学习线性回归原理介绍和功能实现)
线性回归(Linear Regression)模型是最简单的线性模型之一,很具代表性。本文将详细介绍一下机器学习中 线性回归模型的求解过程和编码实现。
内容概要:

1.什么是线性回归
在几何意义上,回归就是找到一条具有代表性的直线或曲线(高维空间的超平面)来拟合输入数据点和输出数据点。线性回归 可以理解为找到 用来拟合输入数据点和输出数据点的 那条具有代表性直线或曲线的过程。
为了理解线性回归的概念,我们可以先从一个实例来引入本文的主题。
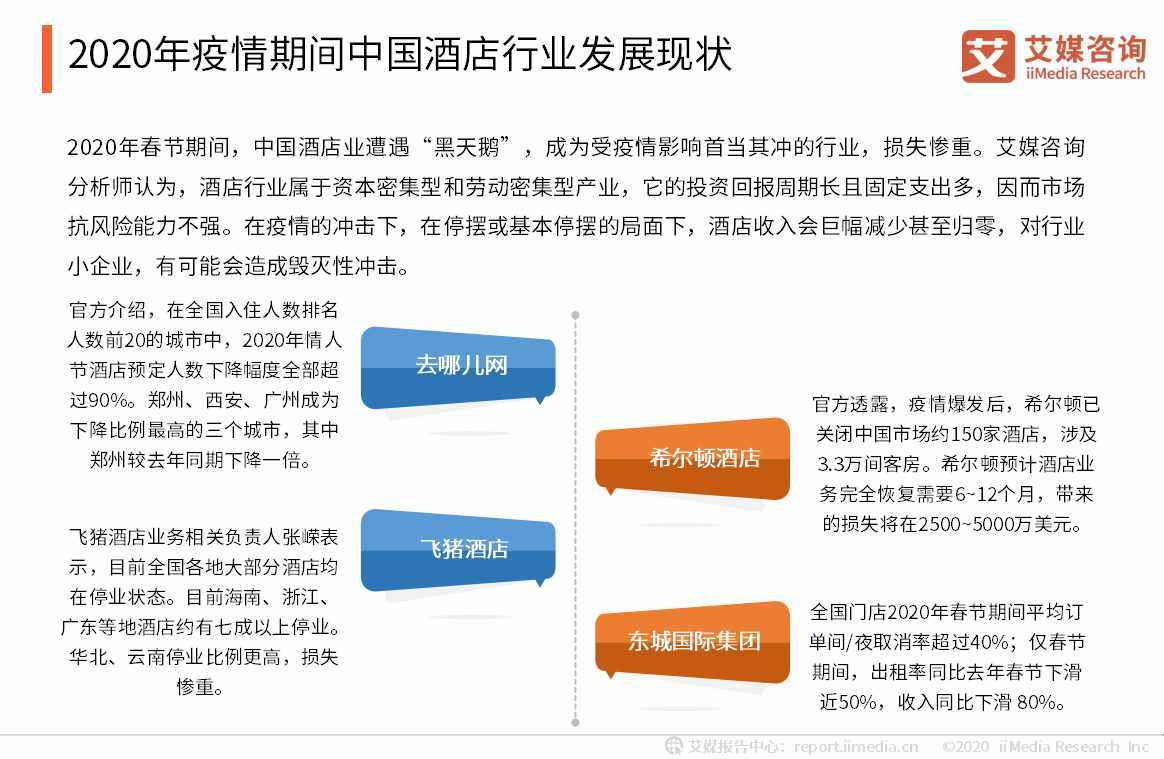
1.1 问题描述----波士顿房价预测
波士顿房价预测 是一个很经典的线性回归案例,这个案例使用的数据集(Boston House Price Dataset)源自 20 世纪 70 年代中期美国人口普查局收集的美国马萨诸塞州波士顿住房价格有关信息。该数据集统计了当地城镇人均犯罪率、城镇非零售业务比例等。共计 13 个指标(特征),第 14 个特征(相当于标签信息)给出了住房的中位数报价。先来看看这组数据,

特征信息翻译参考下图,

1.2 特征,标签和样本
通过上面这个波士顿房价预测的数据集,先引入机器学习中关于数据集的几个概念,
特征:输入变量,即简单线性回归中的 x变量(如颜色,天气,水果等),在这个数据集中,每一列表示一项特征(最后一列是标签 除外),一共13项特征
标签:我们要预测的事物,即简单线性回归中的 y 变量。标签可以是连续值(如房价,股市等),可以是离散值(今天周几,水果好不好吃等),在这个数据集中,最后一列PRICE就是标签
样本:是指数据的特定实例(样本包括训练集和测试集)。在这个数据集中,每一行表示一个样本
备注:该数据集在卡耐基梅隆大学统计与数据科学实验室或 Kaggle 等网站均可下载。下载后,需要删除部分额外的数据描述信息,并将文件另存为 CSV 格式,然后利用之前介绍的 Pandas 来读取数据。
另外,在前面介绍的机器学习框架sklearn(scikit-learn)内置了这个数据集,无需另外下载,只要调用专用的 API 函数即可导入数据,详细信息可参考这篇文章的介绍。
现在我们的任务是,找到这些指标(特征)与房价(目标)之间的关系。由于房价是连续变化的实数,很明显,这个任务属于回归分析。为了找到这些指标(特征)与房价(目标)之间的关系,我们需要构建模型。
2. 构建模型
上面这个表中提供了4个样本,每一个样本都包含了13个特征值和一个标签。现在我们需要将这个房价预测问题进行一般化描述,为构建模型做准备,
X 表示样本;
Y 表示 标签;
{x1,x2,x3...xn}表示数据集中的特征值;
{X(1),X(2),X(3)...X(n)} 表示第几个样本
将波士顿房价数据集一般化的描述结果展示如下,

从数据集提供的信息,影响波士顿房价(标签)的因素有13项(特征值),现在我们希望建立一个模型,当我们输入这13个影响房价因素的量化值后,模型能够帮助我们预测出房价。这个模型用数学公式可以表示为(n=13),

简化一下,

xi是我们数据集中样本的特征值, y^ 就是我们的模型预测结果,w和b 就是我们模型的参数,现在构建模型的问题就转化为如何求解参数w和b了。
3.损失函数(Loss Function)
为了求解模型参数w和b,需要引入损失函数的概念。根据第2章节构建的线性模型,数据集中的每一组x(n)样本 理论上都有对应一个预测值yn^ ,{x1,x2,...,xn }是特征值,表示方式如下,

数据集中的每一组样本 理论上都有一个标签y和一个预测值y^,参考下图,

一组样本对应一个标签值和一个预测值
我们期望构建的模型的预测值y^跟真实值y 差距越小越好,越小说明我们构建的模型越准确,

第一个样本真实值与预测值的差值
m个样本的整体误差表示如下,

m个样本的整体求和表达式
直接相加有个问题,可能会因为正负值得属性,误差可能相消,导致误差不准确。需要用平方和,参考表达式如下,

这样整体的预测值和真实值得差距就可以用真实值与预期值差值的平方求和表示出来了。这个差距我们称为损失。用来表示预测值和真实值得差距的函数就称为损失函数。
将损失函数简化一下表达方式,

损失函数表达式
代入y^m (第m个样本的预测值)计算公式,

损失函数得表达式:

损失函数表达式
损失函数关联的参数 就是w1,w2,...,wn 和b了。我们的目标是使得损失函数值最小,使用得方法就是梯度下降算法。
4.梯度下降算法(Gradient Descent)
到了这一步,现在的问题转化为求取min(L(w1,w2,...,wn,b))。求函数得最小值,我们在高数中一般用的是求导,找到极值点然后代入函数找到最小值。这种通用的方法在特征值比较少的情况一般也没有什么影响,但如果特征量很多时,这种方法就不适用了。这种情况下就需要用到这里即将介绍的 另外一种求取函数最小值得方法------梯度下降算法。
如下坐标轴,

横轴w:
纵轴L(w):
我们的目标是找到函数最小值L(W*),要找到L(W*),首先需要找到W*,那么梯度下降算法是如何找到W*的呢?
方法如下,
1)首先随机初始化一个w0的点,求出这个点的导数值,从图中可以看到w0 这个点的导致值大于0,并且w0>w*,期望下一次要找的w1能往左移,离w*近一点。这里还需要引入一个参数----学习率。下一个点w1可以用如下公式来表示,

学习率ᶇ是正数,w0处的倒数也是正数,找到的下一个点w1比w0要小,在往期望值w* 靠拢。
2)同样的方法,求取w1的下一个点w2,

3)重复操作,直到直到最小的w*。
示例中随机初始化的w0在最小值w*的右边,事实上w0在w*的左边,效果是一样的,w0在左边时,w0处的导数值为负,带入上面的公式,学习率为正,下一个值w1将增大,最终的结果都是往 w* 靠拢。
4.1.学习率(Learning rate)
正数,决定我们呢每次改变W值 改变多少的值,
学习率的选择

如上图所示,需要设置合适的学习率,如果学习率设置过大,w值会在最优解w* 左右两边震荡,无法到达最优解w*;如果w* 设置过来小,将增大到达最优解w*的计算次数,造成执行效率低下,需要更长的时间才能收敛。
所以我们需要找到一个合适的学习率,梯度下降算法才能达到比较好的效果。
这里顺便补充说明一下超参数的概念,模型的参数 称为参数(如这里的w和b),决定模型的参数,称为超参数,比如这里的学习率。
5.求取损失函数的最小值
回到第3节损失函数的表达式,

w和x 用向量表示,

简化后的公式表示如下,

对w,和b参数求偏导,

然后再用梯度下降算法求取函数的最优解,

上图展示了一次更新过程,循环更新,直到得到最终的最优解w1*,w2*,... wn*,b*。通过梯度下降算法我们找到了模型中的这一组参数,带入模型就可以对新样本的预测了。到了这一步,求解线性回归的模型参数已完成,可以得到根据当前数据集拟合的整体误差最小的模型了。
6.线性回归代码实现
这里为了演示上述过程,我们不用框架和库文件,通过编码的方式实现 y = w1 * x + w2 * (x**2) + b 这个线性回归模型的参数求解。展示用梯度下降算法求解模型参数的实现过程。
1)设置数据
###设置数据
X=[12.3,14.3,14.5,14.8,16.1,16.8,16.5,15.3,17.0,17.8,18.7,20.2,22.3,19.3,15.5,16.7,17.2,18.3,19.2,17.3,19.5,19.7,21.2,23.04,23.8,24.6,25.2,25.7,25.9,26.3]y=[11.8,12.7,13.0,11.8,14.3,15.3,13.5,13.8,14.0,14.9,15.7,18.8,20.1,15.0,14.5,14.9,14.8,16.4,17.0,14.8,15.6,16.4,19.0,19.8,20.0,20.3,21.9,22.1,22.4,22.6]
2)显示数据
plt.scatter(X,y)plt.title('DatasetSamples')plt.xlabel('X')plt.ylabel('y')plt.show()数据显示参考下图,

3)拆分数据集
X_train=X[0:20]y_train=y[0:20]n_train=len(X_train)X_test=X[20:]y_test=y[20:]n_test=len(X_test)
4)拟合模型
####Fitmodel:y=w1*x+w2*(x**2)+bepoches=10000w1=-0.1w2=0.1b=0.3lr_w1=0.0lr_w2=0.0lr=0.001forepochinrange(epoches):sum_w1=0.0sum_w2=0.0sum_b=0.0foriinrange(n_train):y_hat=w1*X_train[i]+w2*(X_train[i]**2)+bsum_w1+=(y_train[i]-y_hat)*(-X_train[i])sum_w2+=(y_train[i]-y_hat)*(-X_train[i]**2)sum_b+=(y_train[i]-y_hat)*(-1)#UsingGradientDescenttoupdateparameters(w,b)det_w1=2.0*sum_w1det_w2=2.0*sum_w2det_b=2.0*sum_blr_w1=lr_w1+det_w1**2lr_w2=lr_w2+det_w1**2w1=w1-(1/math.sqrt(lr_w1)*det_w1)w2=w2-(1/math.sqrt(lr_w2)*det_w2)b=b-lr*det_b
5)展示模型拟合的结果
fig,ax=plt.subplots()ax.plot([iforiinrange(10,25)],[w1*i+w2*(i**2)+bforiinrange(10,25)])ax.scatter(X_train,y_train)plt.title('y=w1*x+w2*x^2+b')plt.legend(('Model','DataPoints'),loc='upperleft')plt.show()模型展示的效果图,

6)求解损失
total_loss_train=0foriinrange(n_train):y_hat=y_hat=w1*X_train[i]+w2*(X_train[i]**2)+btotal_loss_train+=(y_hat-y_train[i])**2print("训练集损失值:"+str(total_loss_train))total_loss_test=0foriinrange(n_test):y_hat=y_hat=w1*X_test[i]+w2*(X_test[i]**2)+btotal_loss_test+=(y_hat-y_test[i])**2print("测试集损失值:"+str(total_loss_train))求解的损失参考下图,

总结:
本文通过经典的线性回归案例---波士顿房价预测,介绍了机器学习中线性回归的实现原理,
1)构建表示数据集中 特征值和标签值之间的关系的模型,将线性回归问题转换为求参数wi和b 的问题
2)定义损失函数-----预测值与真实值之间的差距
3)介绍了机器学习中的 求取函数最小值的算法-----梯度下降算法
4)用梯度下降算法求取损失函数的最小值,确定参数wi和b,从而确定模型
5)最后通过编码的方式展示了用梯度下降算法求解模型参数的实现过程